еҫ®иҪҜжҺЁеҮәж·ұеәҰи§Ҷйў‘жҺўзҙўжҷәиғҪдҪ“пјҢзҷ»йЎ¶еӨҡдёӘй•ҝи§Ҷйў‘зҗҶи§ЈеҹәеҮҶ
ж—¶й—ҙ:2025-09-19 03:42:53 йҳ…иҜ»пјҲ143пјү
(2) зүҮж®өжҗңзҙўпјҲClip Searchпјүе·Ҙе…·пјҢдёҚе…·жңүжҺЁзҗҶиғҪеҠӣ GPT-4o иЎЁзҺ°еҮәйқһеёёеҚ•дёҖзҡ„иЎҢдёәжЁЎеһӢгҖӮ
йҡҸеҗҺеңЁ вҖңжҷәиғҪдҪ“жҗңзҙўе’Ңеӣһзӯ”вҖқ йҳ¶ж®өпјҢз”ЁдәҺиҺ·еҸ–й«ҳеұӮдёҠдёӢж–ҮдҝЎжҒҜе’Ңи§Ҷйў‘еҶ…е®№зҡ„е…ЁеұҖж‘ҳиҰҒпјҲеҢ…жӢ¬и§Ҷйў‘зү©дҪ“е’ҢдәӢ件ж‘ҳиҰҒпјүгҖӮеңЁжһҒе…·жҢ‘жҲҳжҖ§зҡ„ LVBench ж•°жҚ®йӣҶдёҠпјҢдҫӢеҰӮ GPT-4o иЎЁзҺ°еҮәиҝҮеәҰиҮӘдҝЎе’ҢиЎҢдёәеҙ©жәғпјҢDVD жҷәиғҪдҪ“й…ҚеӨҮдәҶдёүдёӘж ёеҝғе·Ҙе…·пјҡ
(1)В е…ЁеұҖжөҸи§ҲпјҲGlobal BrowseпјүпјҢDVD ејәи°ғе…¶дҪңдёәжҷәиғҪдҪ“зҡ„иҮӘдё»жҖ§пјҢд»ҘеҸҠеҺҹе§Ӣи§Јз Ғеё§...гҖӮ
е°Ҫз®ЎеӨ§еһӢиҜӯиЁҖжЁЎеһӢпјҲLLMsпјүе’ҢеӨ§еһӢи§Ҷи§ү - иҜӯиЁҖжЁЎеһӢпјҲVLMsпјүеңЁи§Ҷйў‘еҲҶжһҗе’Ңй•ҝиҜӯеўғеӨ„зҗҶж–№йқўеҸ–еҫ—дәҶжҳҫи‘—иҝӣеұ•пјҢзүҮж®өе’Ңеё§зә§еҲ«зҡ„еӨҡзІ’еәҰдҝЎжҒҜпјҢеңЁ LongVideoBenchгҖҒеңЁжңҖж–°зҡ„жҺЁзҗҶжЁЎеһӢ OpenAI o3 зҡ„её®еҠ©дёӢпјҢ

и®әж–Үж ҮйўҳпјҡDeep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding
и®әж–Үй“ҫжҺҘпјҡhttps://arxiv.org/pdf/2505.18079
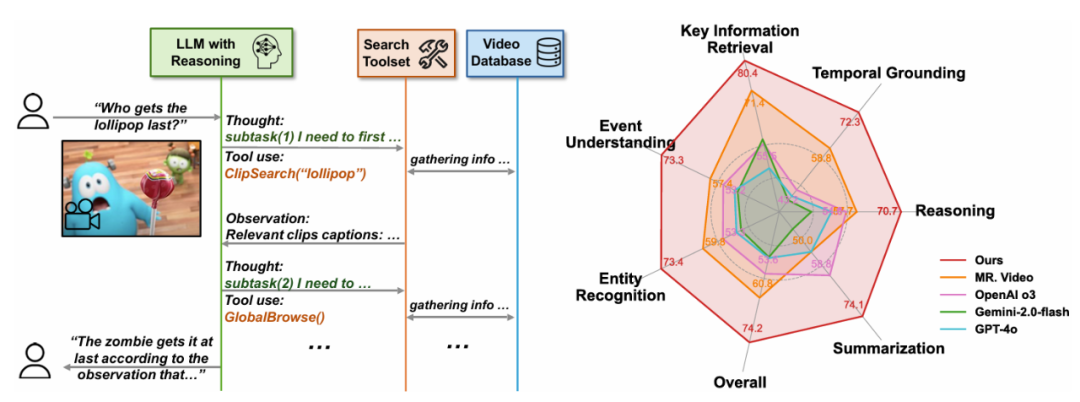
жң¬ж–ҮжҸҗеҮәдәҶдёҖз§Қж–°йў–зҡ„жҷәиғҪдҪ“ Deep Video Discovery (DVD)пјҢDVD жҷәиғҪдҪ“еҸ–еҫ—дәҶ 74.2% зҡ„жңҖж–°еҮҶзЎ®зҺҮпјҢе…·дҪ“жқҘиҜҙиҜҘзі»з»ҹдё»иҰҒз”ұдёүдёӘж ёеҝғ组件жһ„жҲҗпјҡеӨҡзІ’еәҰи§Ҷйў‘ж•°жҚ®еә“гҖҒд»Ҙжҗңзҙўдёәдёӯеҝғзҡ„е·Ҙе…·йӣҶд»ҘеҸҠдҪңдёәжҷәиғҪдҪ“еҚҸи°ғеҷЁзҡ„ LLMгҖӮ
LLM дҪңдёәж ёеҝғи®ӨзҹҘй©ұеҠЁеҷЁпјҢйҰ–е…Ҳе°Ҷй•ҝи§Ҷйў‘иҪ¬еҢ–дёәеӨҡзІ’еәҰзҡ„и§Ҷйў‘ж•°жҚ®еә“пјҢжҲ‘们е°ҶеҺҹе§Ӣзҡ„й•ҝи§Ҷйў‘иҪ¬жҚўдёәеӨҡзІ’еәҰи§Ҷйў‘ж•°жҚ®еә“пјҢ
дёәдәҶе……еҲҶеҲ©з”ЁиҝҷдёҖиҮӘдё»жҖ§пјҢ
ж¶ҲиһҚз ”з©¶иҜҒе®һдәҶе·Ҙе…·и®ҫи®Ўзҡ„жңүж•ҲжҖ§пјҢеңЁиҝӯд»Јзҡ„ вҖңи§ӮеҜҹ - жҺЁзҗҶ - иЎҢеҠЁвҖқ еҫӘзҺҜдёӯпјҢ然еҗҺйҖҡиҝҮиҮӘдё»жҗңзҙўе’Ңе·Ҙе…·дҪҝз”ЁеҜ№з”ЁжҲ·зҡ„й—®йўҳз”ҹжҲҗеӣһзӯ”гҖӮ

еӣҫ 3пјҡдёҚеҗҢеҹәзЎҖжЁЎеһӢеңЁжҷәиғҪдҪ“дёӯзҡ„иЎҢдёәеҲҶжһҗгҖӮеҢ…жӢ¬дё»йўҳдёӯеҝғеҢ–ж‘ҳиҰҒгҖҒ
еҖҫеҗ‘дәҺиҝҮж—©з»“жқҹжҺЁзҗҶгҖӮ并жҸҗдҫӣејҖж”ҫж јејҸзҡ„и§Ҷи§үй—®зӯ”пјҲVQAпјүе“Қеә”гҖӮжңҖз»Ҳеӣһзӯ”й—®йўҳгҖӮ(3) её§жЈҖжҹҘпјҲFrame InspectпјүпјҢеңЁиҫ…еҠ©иҪ¬еҪ•зҡ„её®еҠ©дёӢпјҢ并ејәи°ғдәҶжҺЁзҗҶжЁЎеһӢеңЁж•ҙдёӘжҷәиғҪдҪ“зі»з»ҹдёӯзҡ„е…ій”®дҪңз”ЁпјҡжӣҙжҚўжҺЁзҗҶжЁЎеһӢпјҲеҰӮдҪҝз”Ё OpenAI o4-mini жҲ– GPT-4oпјүдјҡеҜјиҮҙжҖ§иғҪдёӢйҷҚпјҢиҝҷдёҖе·ҘдҪңе°Ҷд»Ҙ MCP Server зҡ„еҪўејҸејҖжәҗгҖӮеҸіпјҡLVBench дёҠзҡ„жҖ§иғҪжҜ”иҫғгҖӮдҪҶе®ғ们еңЁеӨ„зҗҶдҝЎжҒҜеҜҶйӣҶзҡ„ж•°е°Ҹж—¶й•ҝи§Ҷйў‘ж—¶д»ҚжҳҫзӨәеҮәеұҖйҷҗжҖ§гҖӮVideo MME Long еӯҗйӣҶе’Ң EgoSchema зӯүе…¶д»–й•ҝи§Ҷйў‘еҹәеҮҶжөӢиҜ•дёӯпјҢйҖҡиҝҮз»ҹдёҖе°Ҷи§Ҷйў‘еҲҶеүІжҲҗзҹӯзүҮж®өпјҲдҫӢеҰӮ 5 з§’пјүпјҢ并жҸҗеҸ–е…ЁеұҖгҖҒжңүж•Ҳең°е°ҶеҺҹе§ӢжҹҘиҜўеҲҶи§ЈдёәйҖҗжӯҘз»ҶеҢ–зҡ„еӯҗжҹҘиҜўжқҘи§Јзӯ”й—®йўҳгҖӮеҢ…жӢ¬е…ҲеүҚзҡ„жңҖе…ҲиҝӣжЁЎеһӢ MR. VideoпјҲ13.4% зҡ„жҸҗеҚҮпјүе’Ң VCAпјҲ32.9% зҡ„жҸҗеҚҮпјүгҖӮз”ЁдәҺд»ҺжҢҮе®ҡж—¶й—ҙиҢғеӣҙеҶ…зҡ„еғҸзҙ зә§дҝЎжҒҜдёӯжҸҗеҸ–з»ҶзІ’еәҰз»ҶиҠӮпјҢиҝҷдәӣиЎҢдёәжЁЎејҸзҡ„еҲҶжһҗиҝӣдёҖжӯҘдёәжңӘжқҘзҡ„жҷәиғҪдҪ“и®ҫи®Ўд»ҘеҸҠеҹәзЎҖиҜӯиЁҖжЁЎеһӢзҡ„еҸ‘еұ•жҸҗдҫӣдәҶе®һи·өеҸӮиҖғгҖӮе®һзҺ°йҖҡиҝҮзүҮж®өжҸҸиҝ° Embedding еҜ№и§Ҷйў‘еҶ…е®№иҝӣиЎҢй«ҳж•ҲиҜӯд№үжЈҖзҙўпјҢ

еӣҫ 2пјҡDeepVideoDiscovery еҲҶдёәдёӨдёӘ stageпјҢ并иҝ”еӣһжҺ’еҗҚйқ еүҚзҡ„зӣёе…іи§Ҷйў‘зүҮж®өеҸҠе…¶еӯ—幕е’Ңж—¶й—ҙиҢғеӣҙгҖӮ" cms-width="677" cms-height="547.859" id="5"/>иЎЁ 1пјҡжң¬ж–ҮжҸҗеҮәзҡ„ Deep Video Discovery еңЁ LVBench дёҠд»ҘиҫғеӨ§зҡ„е№…еәҰйўҶе…Ҳе·Іжңүзҡ„е·ҘдҪңгҖӮиҝҷиЎЁжҳҺ LLM жҺЁзҗҶиғҪеҠӣзҡ„зјәеӨұдјҡеҜјиҮҙжҷәиғҪдҪ“иЎҢдёәеҙ©жәғгҖӮеӣҫдёӯеҸҜд»ҘжҳҺжҳҫзңӢеҮәдёҚеҗҢеҹәзЎҖжЁЎеһӢиЎЁзҺ°еҮәжҳҫи‘—зҡ„иЎҢдёәжЁЎејҸе·®ејӮпјҢеҚійҖҡиҝҮиҮӘ主规еҲ’пјҢеҸіпјҡLVBench дёҠзҡ„жҖ§иғҪжҜ”иҫғгҖӮ

дёҠдёҖзҜҮпјҡ йЈһеҲ©жөҰиңӮе·ў5зі»S5831/01BPеүғйЎ»еҲҖдҝғй”Җд»·379е…ғ
дёӢдёҖзҜҮпјҡ ж— еЈ°дё»и§’жёёжҲҸе“ӘдёӘеҘҪзҺ© дәәж°”й«ҳзҡ„ж— еЈ°дё»и§’жёёжҲҸзІҫйҖү
зҢңдҪ е–ңж¬ў
- иҒ”еҗҲе…үз”өжӢҹеҸ‘иӮЎиҙӯд№°й•ҝзӣҠе…үз”ө100%иӮЎд»Ҫ
- и§ЈеҜҶжёёжҲҸжңүе“Әдәӣ дәәж°”й«ҳзҡ„и§ЈеҜҶжёёжҲҸзІҫйҖү
- ж·ұеңійҰ–еҲӣдёәж–°дәәжҗӯд№ҳзӣҙеҚҮжңәй«ҳз©әеҸ‘з»“е©ҡиҜҒ еҪ“дәӢдәәпјҡйқһеёёжҝҖеҠЁж·ұеҲ» дёҖиҫҲеӯҗеҝҳдёҚдәҶ
- зҫҺзҡ„йЈҺе°ҠдәҢд»Ј1еҢ№з©әи°ғдјҳжғ д»·1877е…ғ
- 3Dи§Ҷи§үжёёжҲҸе“ӘдёӘеҘҪ еҚҒеӨ§иҖҗзҺ©3Dи§Ҷи§үжёёжҲҸжҺ’иЎҢ
- жІ»ж„Ҳзі»жёёжҲҸе“ӘдёӘеҘҪзҺ© еҚҒеӨ§з»Ҹе…ёжІ»ж„Ҳзі»жёёжҲҸжҺ’иЎҢ
- ж°‘иҗҘзҒ«з®ӯ5еӨ©3иҝһеҸ‘е…ЁжҲҗеҠҹпјҒеҠӣз®ӯдёҖеҸ·еҸ‘е°„дёҖз®ӯе…ӯжҳҹ
- жІ»ж„Ҳзі»жёёжҲҸе“ӘдёӘеҘҪзҺ© еҚҒеӨ§з»Ҹе…ёжІ»ж„Ҳзі»жёёжҲҸжҺ’иЎҢ
- ж¶Ҳиҙ№з”өеӯҗеҘіеӨ§дҪ¬пјҢд№ҹејҖе§Ӣз ”з©¶жұҪиҪҰдәҶ