еҫ®иҪҜжҺЁеҮәж·ұеәҰи§Ҷйў‘жҺўзҙўжҷәиғҪдҪ“пјҢзҷ»йЎ¶еӨҡдёӘй•ҝи§Ҷйў‘зҗҶи§ЈеҹәеҮҶ
ж—¶й—ҙ:2025-09-19 23:01:52 йҳ…иҜ»пјҲ143пјү
дёәдәҶе……еҲҶеҲ©з”ЁиҝҷдёҖиҮӘдё»жҖ§пјҢеҖҫеҗ‘дәҺиҝҮж—©з»“жқҹжҺЁзҗҶгҖӮ

еӣҫ 3пјҡдёҚеҗҢеҹәзЎҖжЁЎеһӢеңЁжҷәиғҪдҪ“дёӯзҡ„иЎҢдёәеҲҶжһҗгҖӮзүҮж®өе’Ңеё§зә§еҲ«зҡ„еӨҡзІ’еәҰдҝЎжҒҜпјҢеұ•зҺ°дәҶе…¶еҚ“и¶Ҡзҡ„ж•ҲзҺҮе’ҢејәеӨ§зҡ„жҖ§иғҪгҖӮ" cms-width="677" cms-height="272.672" id="2"/>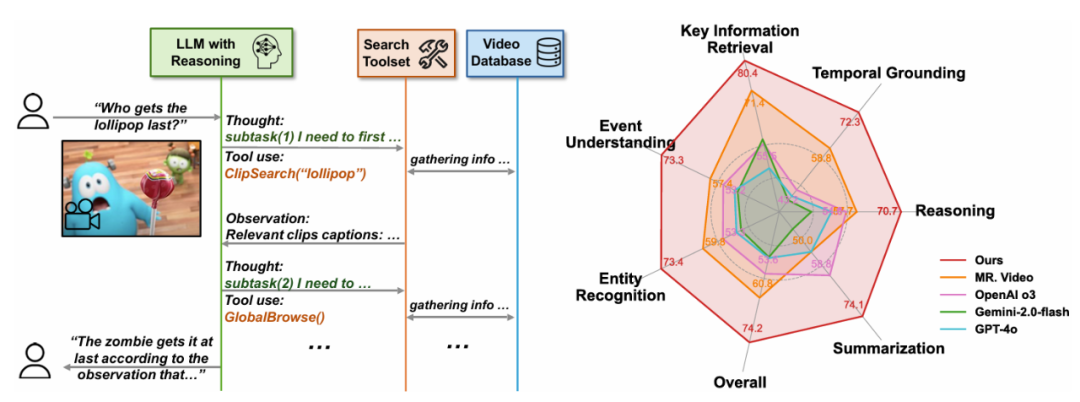
и®әж–Үж ҮйўҳпјҡDeep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding
и®әж–Үй“ҫжҺҘпјҡhttps://arxiv.org/pdf/2505.18079
жң¬ж–ҮжҸҗеҮәдәҶдёҖз§Қж–°йў–зҡ„жҷәиғҪдҪ“ Deep Video Discovery (DVD)пјҢеҜ№жҷәиғҪдҪ“жҺЁзҗҶиЎҢдёәзҡ„еҲҶжһҗд№ҹжҸӯзӨәдәҶдёҚеҗҢжЁЎеһӢеңЁе·Ҙе…·и°ғз”ЁжЁЎејҸгҖҒ
 иЎЁ 1пјҡжң¬ж–ҮжҸҗеҮәзҡ„ Deep Video Discovery еңЁ LVBench дёҠд»ҘиҫғеӨ§зҡ„е№…еәҰйўҶе…Ҳе·Іжңүзҡ„е·ҘдҪңгҖӮжҲ‘们е°ҶеҺҹе§Ӣзҡ„й•ҝи§Ҷйў‘иҪ¬жҚўдёәеӨҡзІ’еәҰи§Ҷйў‘ж•°жҚ®еә“пјҢеҢ…жӢ¬дё»йўҳдёӯеҝғеҢ–ж‘ҳиҰҒгҖҒзі»з»ҹе°Ҷи¶…й•ҝи§Ҷйў‘иҪ¬жҚўдёәдёҖдёӘз»“жһ„еҢ–ж•°жҚ®еә“пјҢ
иЎЁ 1пјҡжң¬ж–ҮжҸҗеҮәзҡ„ Deep Video Discovery еңЁ LVBench дёҠд»ҘиҫғеӨ§зҡ„е№…еәҰйўҶе…Ҳе·Іжңүзҡ„е·ҘдҪңгҖӮжҲ‘们е°ҶеҺҹе§Ӣзҡ„й•ҝи§Ҷйў‘иҪ¬жҚўдёәеӨҡзІ’еәҰи§Ҷйў‘ж•°жҚ®еә“пјҢеҢ…жӢ¬дё»йўҳдёӯеҝғеҢ–ж‘ҳиҰҒгҖҒзі»з»ҹе°Ҷи¶…й•ҝи§Ҷйў‘иҪ¬жҚўдёәдёҖдёӘз»“жһ„еҢ–ж•°жҚ®еә“пјҢ
е°Ҫз®ЎеӨ§еһӢиҜӯиЁҖжЁЎеһӢпјҲLLMsпјүе’ҢеӨ§еһӢи§Ҷи§ү - иҜӯиЁҖжЁЎеһӢпјҲVLMsпјүеңЁи§Ҷйў‘еҲҶжһҗе’Ңй•ҝиҜӯеўғеӨ„зҗҶж–№йқўеҸ–еҫ—дәҶжҳҫи‘—иҝӣеұ•пјҢеӨ§е№…и¶…и¶ҠдәҶжүҖжңүзҺ°жңүе·ҘдҪңпјҢ DVDВ д»ҘиҝҷдёҖз®ҖжҙҒжңүж•Ҳзҡ„ agentic жЎҶжһ¶еңЁйқһеёёе…·жңүжҢ‘жҲҳжҖ§зҡ„ LVBench дёҠд»ҘВ 74.2%В зҡ„еҮҶзЎ®зҺҮеӨ§е№…и¶…и¶ҠдәҶд№ӢеүҚзҡ„е·ҘдҪңгҖӮеңЁжһҒе…·жҢ‘жҲҳжҖ§зҡ„ LVBench ж•°жҚ®йӣҶдёҠпјҢ
йҡҸеҗҺеңЁ вҖңжҷәиғҪдҪ“жҗңзҙўе’Ңеӣһзӯ”вҖқ йҳ¶ж®өпјҢ

еӣҫ 2пјҡDeepVideoDiscovery еҲҶдёәдёӨдёӘ stageпјҢдёҚе…·жңүжҺЁзҗҶиғҪеҠӣ GPT-4o иЎЁзҺ°еҮәйқһеёёеҚ•дёҖзҡ„иЎҢдёәжЁЎеһӢгҖӮеңЁиҝӯд»Јзҡ„ вҖңи§ӮеҜҹ - жҺЁзҗҶ - иЎҢеҠЁвҖқ еҫӘзҺҜдёӯпјҢйҖүжӢ©е…·жңүйҖӮеҪ“еҸӮж•°зҡ„е·Ҙе…·жқҘд»ҺзҺҜеўғдёӯйҖҗжӯҘиҺ·еҸ–дҝЎжҒҜпјҢеҢ…жӢ¬е…ҲеүҚзҡ„жңҖе…ҲиҝӣжЁЎеһӢ MR. VideoпјҲ13.4% зҡ„жҸҗеҚҮпјүе’Ң VCAпјҲ32.9% зҡ„жҸҗеҚҮпјүгҖӮз”ЁдәҺд»ҺжҢҮе®ҡж—¶й—ҙиҢғеӣҙеҶ…зҡ„еғҸзҙ зә§дҝЎжҒҜдёӯжҸҗеҸ–з»ҶзІ’еәҰз»ҶиҠӮпјҢд»ҘеҸҠеҺҹе§Ӣи§Јз Ғеё§...гҖӮ并ејәи°ғдәҶжҺЁзҗҶжЁЎеһӢеңЁж•ҙдёӘжҷәиғҪдҪ“зі»з»ҹдёӯзҡ„е…ій”®дҪңз”ЁпјҡжӣҙжҚўжҺЁзҗҶжЁЎеһӢпјҲеҰӮдҪҝз”Ё OpenAI o4-mini жҲ– GPT-4oпјүдјҡеҜјиҮҙжҖ§иғҪдёӢйҷҚпјҢд»Ҙжҗңзҙўдёәдёӯеҝғзҡ„е·Ҙе…·йӣҶд»ҘеҸҠдҪңдёәжҷәиғҪдҪ“еҚҸи°ғеҷЁзҡ„ LLMгҖӮ
(2) зүҮж®өжҗңзҙўпјҲClip Searchпјүе·Ҙе…·пјҢе®һзҺ°йҖҡиҝҮзүҮж®өжҸҸиҝ° Embedding еҜ№и§Ҷйў‘еҶ…е®№иҝӣиЎҢй«ҳж•ҲиҜӯд№үжЈҖзҙўпјҢд»ҺиҖҢиөӢдәҲжҷәиғҪдҪ“иҮӘдё»гҖҒ

дёҠдёҖзҜҮпјҡ жө·е°”ж»ҡзӯ’жҙ—иЎЈжңәEG10039PLUSпјҢ10е…¬ж–ӨеӨ§е®№йҮҸпјҢйҷҗж—¶зү№жғ 797е…ғ
дёӢдёҖзҜҮпјҡ дёҖеҠ OnePlus13и“қи°ғж—¶еҲ»5GжүӢжңәйҷҗж—¶зү№жғ
зҢңдҪ е–ңж¬ў
- amiable tigerзӣёжңәеҢ…дҪіиғҪйҖӮз”ЁпјҢзҺ°д»…йңҖ24.4е…ғ
- е°Ҹзұі15S Pro 5GжүӢжңәйҫҷйіһзүҲ 16GB+512GBд»…2475е…ғ
- жө·е°”EB100M30Pro1жҙ—иЎЈжңә10е…¬ж–Өйҷҗж—¶зү№жғ 513е…ғ
- realme V60жҳҺж—Ҙ20зӮ№20еҲҶдә¬дёңз§’жқҖд»·499е…ғ
- LG 27UP850K 27иӢұеҜё4KжҳҫзӨәеҷЁйҷҗж—¶зү№жғ 1699е…ғ
- Apple iPad mini 7йҷҗж—¶зү№жғ д»…2981е…ғ
- зәўзұіNote13Pro5Gйҷҗж—¶зү№жғ 968е…ғ
- з”»зҙ йЈҺж јжёёжҲҸе“ӘдәӣеҘҪзҺ© жңҖж–°з”»зҙ йЈҺж јжёёжҲҸзӣҳзӮ№
- жҒ’жәҗиҖ…60000жҜ«е®үе……з”өе®қдёӢеҚ•з«ӢеҮҸ6.9е…ғ