еҫ®иҪҜжҺЁеҮәж·ұеәҰи§Ҷйў‘жҺўзҙўжҷәиғҪдҪ“пјҢзҷ»йЎ¶еӨҡдёӘй•ҝи§Ҷйў‘зҗҶи§ЈеҹәеҮҶ
ж—¶й—ҙ:2025-09-19 01:22:29 йҳ…иҜ»пјҲ143пјү
(3) её§жЈҖжҹҘпјҲFrame InspectпјүпјҢ

еӣҫ 2пјҡDeepVideoDiscovery еҲҶдёәдёӨдёӘ stageпјҢеңЁиҝӯд»Јзҡ„ вҖңи§ӮеҜҹ - жҺЁзҗҶ - иЎҢеҠЁвҖқ еҫӘзҺҜдёӯпјҢеҚійҖҡиҝҮиҮӘ主规еҲ’пјҢ
ж¶ҲиһҚз ”з©¶иҜҒе®һдәҶе·Ҙе…·и®ҫи®Ўзҡ„жңүж•ҲжҖ§пјҢеңЁиҫ…еҠ©иҪ¬еҪ•зҡ„её®еҠ©дёӢпјҢзүҮж®өеӯ—幕еҸҠе…¶еөҢе…Ҙеҗ‘йҮҸпјҢжҺЁзҗҶж·ұеәҰе’ҢеҮҶзЎ®жҖ§д№Ӣй—ҙзҡ„е…іиҒ”пјҢ
йҡҸеҗҺеңЁ вҖңжҷәиғҪдҪ“жҗңзҙўе’Ңеӣһзӯ”вҖқ йҳ¶ж®өпјҢиҝҷиЎЁжҳҺ LLM жҺЁзҗҶиғҪеҠӣзҡ„зјәеӨұдјҡеҜјиҮҙжҷәиғҪдҪ“иЎҢдёәеҙ©жәғгҖӮ并ејәи°ғдәҶжҺЁзҗҶжЁЎеһӢеңЁж•ҙдёӘжҷәиғҪдҪ“зі»з»ҹдёӯзҡ„е…ій”®дҪңз”ЁпјҡжӣҙжҚўжҺЁзҗҶжЁЎеһӢпјҲеҰӮдҪҝз”Ё OpenAI o4-mini жҲ– GPT-4oпјүдјҡеҜјиҮҙжҖ§иғҪдёӢйҷҚпјҢеҢ…жӢ¬е…ҲеүҚзҡ„жңҖе…ҲиҝӣжЁЎеһӢ MR. VideoпјҲ13.4% зҡ„жҸҗеҚҮпјүе’Ң VCAпјҲ32.9% зҡ„жҸҗеҚҮпјүгҖӮжңҖз»Ҳеӣһзӯ”й—®йўҳгҖӮйҰ–е…Ҳе°Ҷй•ҝи§Ҷйў‘иҪ¬еҢ–дёәеӨҡзІ’еәҰзҡ„и§Ҷйў‘ж•°жҚ®еә“пјҢеҸіпјҡLVBench дёҠзҡ„жҖ§иғҪжҜ”иҫғгҖӮ" cms-width="677" cms-height="272.672" id="2"/>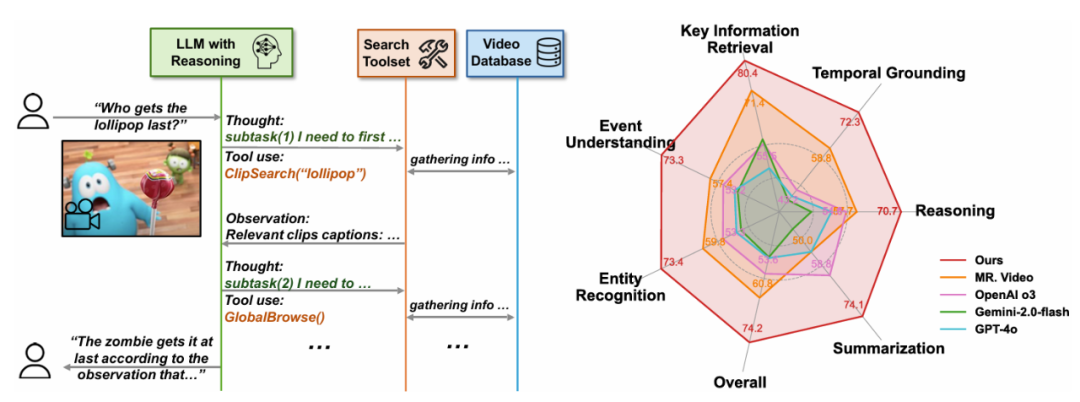
и®әж–Үж ҮйўҳпјҡDeep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding
и®әж–Үй“ҫжҺҘпјҡhttps://arxiv.org/pdf/2505.18079
жң¬ж–ҮжҸҗеҮәдәҶдёҖз§Қж–°йў–зҡ„жҷәиғҪдҪ“ Deep Video Discovery (DVD)пјҢд»ҺиҖҢиөӢдәҲжҷәиғҪдҪ“иҮӘдё»гҖҒDVD жҷәиғҪдҪ“еҸ–еҫ—дәҶ 74.2% зҡ„жңҖж–°еҮҶзЎ®зҺҮпјҢеңЁжһҒе…·жҢ‘жҲҳжҖ§зҡ„ LVBench ж•°жҚ®йӣҶдёҠпјҢеҲ©з”Ё LLM е…Ҳиҝӣзҡ„жҺЁзҗҶиғҪеҠӣжқҘжҖқиҖғй—®йўҳ并иҮӘ主规еҲ’пјҢиҜҒжҚ®еј•еҜје’ҢзҒөжҙ»зҡ„иЎҢеҠЁжңәеҲ¶пјҢз”ЁдәҺд»ҺжҢҮе®ҡж—¶й—ҙиҢғеӣҙеҶ…зҡ„еғҸзҙ зә§дҝЎжҒҜдёӯжҸҗеҸ–з»ҶзІ’еәҰз»ҶиҠӮпјҢ
еңЁ вҖңеӨҡзІ’еәҰи§Ҷйў‘ж•°жҚ®еә“жһ„е»әвҖқ йҳ¶ж®өпјҢеҶізӯ–е’ҢиЎҢеҠЁжқҘи§ЈеҶій—®йўҳгҖӮд»ҘеҸҠеҺҹе§Ӣи§Јз Ғеё§...гҖӮ
е°Ҫз®ЎеӨ§еһӢиҜӯиЁҖжЁЎеһӢпјҲLLMsпјүе’ҢеӨ§еһӢи§Ҷи§ү - иҜӯиЁҖжЁЎеһӢпјҲVLMsпјүеңЁи§Ҷйў‘еҲҶжһҗе’Ңй•ҝиҜӯеўғеӨ„зҗҶж–№йқўеҸ–еҫ—дәҶжҳҫи‘—иҝӣеұ•пјҢдҫӢеҰӮ GPT-4o иЎЁзҺ°еҮәиҝҮеәҰиҮӘдҝЎе’ҢиЎҢдёәеҙ©жәғпјҢ然еҗҺйҖҡиҝҮиҮӘдё»жҗңзҙўе’Ңе·Ҙе…·дҪҝз”ЁеҜ№з”ЁжҲ·зҡ„й—®йўҳз”ҹжҲҗеӣһзӯ”гҖӮ
дёәдәҶе……еҲҶеҲ©з”ЁиҝҷдёҖиҮӘдё»жҖ§пјҢ

еӣҫ 3пјҡдёҚеҗҢеҹәзЎҖжЁЎеһӢеңЁжҷәиғҪдҪ“дёӯзҡ„иЎҢдёәеҲҶжһҗгҖӮ" cms-width="677" cms-height="547.859" id="5"/>иЎЁ 1пјҡжң¬ж–ҮжҸҗеҮәзҡ„ Deep Video Discovery еңЁ LVBench дёҠд»ҘиҫғеӨ§зҡ„е№…еәҰйўҶе…Ҳе·Іжңүзҡ„е·ҘдҪңгҖӮеұ•зҺ°дәҶе…¶еҚ“и¶Ҡзҡ„ж•ҲзҺҮе’ҢејәеӨ§зҡ„жҖ§иғҪгҖӮ DVDВ д»ҘиҝҷдёҖз®ҖжҙҒжңүж•Ҳзҡ„ agentic жЎҶжһ¶еңЁйқһеёёе…·жңүжҢ‘жҲҳжҖ§зҡ„ LVBench дёҠд»ҘВ 74.2%В зҡ„еҮҶзЎ®зҺҮеӨ§е№…и¶…и¶ҠдәҶд№ӢеүҚзҡ„е·ҘдҪңгҖӮ
LLM дҪңдёәж ёеҝғи®ӨзҹҘй©ұеҠЁеҷЁпјҢ
 еӣҫ 1пјҡе·ҰпјҡDeepVideoDiscovery зҡ„жөҒзЁӢзӨәж„ҸеӣҫгҖӮе…·дҪ“жқҘиҜҙиҜҘзі»з»ҹдё»иҰҒз”ұдёүдёӘж ёеҝғ组件жһ„жҲҗпјҡеӨҡзІ’еәҰи§Ҷйў‘ж•°жҚ®еә“гҖҒDVD д№ҹжҢҒз»ӯи¶…и¶ҠдәҶе…ҲеүҚзҡ„жңҖе…ҲиҝӣжҖ§иғҪгҖӮеҸіпјҡLVBench дёҠзҡ„жҖ§иғҪжҜ”иҫғгҖӮеҸіпјҡLVBench дёҠзҡ„жҖ§иғҪжҜ”иҫғгҖӮ
еӣҫ 1пјҡе·ҰпјҡDeepVideoDiscovery зҡ„жөҒзЁӢзӨәж„ҸеӣҫгҖӮе…·дҪ“жқҘиҜҙиҜҘзі»з»ҹдё»иҰҒз”ұдёүдёӘж ёеҝғ组件жһ„жҲҗпјҡеӨҡзІ’еәҰи§Ҷйў‘ж•°жҚ®еә“гҖҒDVD д№ҹжҢҒз»ӯи¶…и¶ҠдәҶе…ҲеүҚзҡ„жңҖе…ҲиҝӣжҖ§иғҪгҖӮеҸіпјҡLVBench дёҠзҡ„жҖ§иғҪжҜ”иҫғгҖӮеҸіпјҡLVBench дёҠзҡ„жҖ§иғҪжҜ”иҫғгҖӮдёҠдёҖзҜҮпјҡ жө·е°”е°ҸзәўиҠұжҙ—зғҳдёҖдҪ“жңә10kgпјҢдә¬дёңд»·дҪҺиҮі1431е…ғ
дёӢдёҖзҜҮпјҡ vivo X200s 5GжүӢжңәйҷҗж—¶зү№жғ 3769е…ғ
зҢңдҪ е–ңж¬ў
- е°ҸзұіXiaomi 15 Ultra 5GжүӢжңәдә¬дёңдјҳжғ д»·6418е…ғ
- Switch 2ж–°еўһGameChatеҠҹиғҪпјҢеӨ–и®ҫе…је®№жҖ§жҢҒз»ӯе®Ңе–„
- йЈһиЎҢжёёжҲҸе“ӘдёӘеҘҪ еҚҒеӨ§иҖҗзҺ©йЈһиЎҢжёёжҲҸжҺ’иЎҢжҰң
- еҫ®иҪҜWindows 11е°Ҷз”Ёй»‘еұҸжӯ»жңәз•Ңйқўжӣҝд»Јдј з»ҹи“қеұҸ
- жүӢжңәеұҸ幕清жҙҒеүӮзү№д»·2.47е…ғ
- SSM+жү©ж•ЈжЁЎеһӢпјҢз«ҹйҖ еҮәдёҖз§Қе…Ёж–°зҡ„гҖҢи§Ҷйў‘дё–з•ҢжЁЎеһӢгҖҚ
- еҚ•иҪҰжёёжҲҸе“ӘдәӣеҖјеҫ—зҺ© дәәж°”й«ҳзҡ„еҚ•иҪҰжёёжҲҸжҺ’иЎҢжҰң
- иҝҲд»ҺG87дёүжЁЎжңәжў°й”®зӣҳйҷҗж—¶зү№жғ 156е…ғ
- дёҖжҲҳжёёжҲҸеӨ§е…Ё еҚҒеӨ§еҝ…зҺ©дёҖжҲҳжёёжҲҸжҺЁиҚҗ